Tabla de Contenidos
EN CONSTRUCCIÓN

Trie
Idea intuitiva
Un Trie es una estructura de datos del tipo diccionario cuyas claves son strings.
En breve veremos la flexibilidad de los tries; pero bajo esta definición, en principio podemos simularlo con un map:
/// Falso trie map<string, int> T; T["edad"] = 16 T["altura"] = 174
Al escribir nosotros mismos la estructura, podemos mejorarla para añadir operaciones que map no soporta, a la vez que mejoramos la eficiencia.
¿Qué son?
Concretamente, llamamos Trie a un árbol con raíz donde cada arco está etiquetado con un carácter, y dos arcos con la misma etiqueta no pueden salir del mismo nodo. De esta manera, cada nodo representa al string que se obtiene de mirar el camino desde la raíz a él.
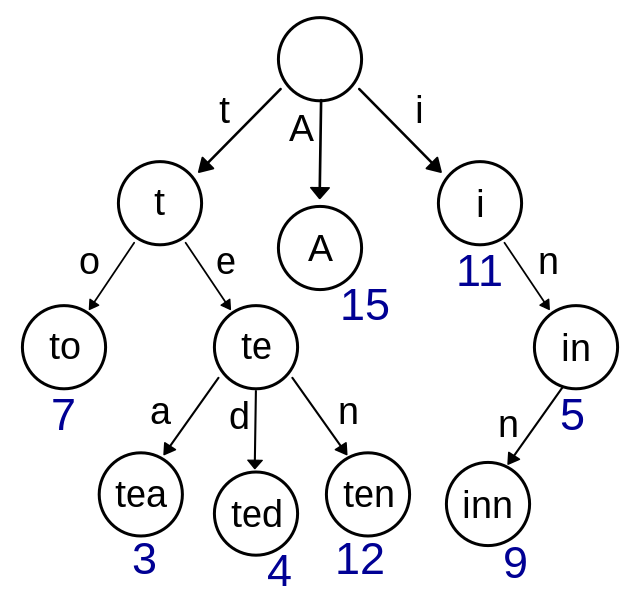 Imagen: Wikipedia.
Imagen: Wikipedia.
Trie con contenido: “A” : 15, “to” : 7, “tea” : 3, “ted” : 4, “ten” : 12, “i” : 11, “in” : 5, “inn” : 9.
Los nodos no guardan las claves sino el valor (en azul), las etiquetas están sólo a modo de ilustración.
Operaciones
Las operaciones básicas de todo diccionario son:
insertar(clave, valor): asocia el valor a la clavebuscar(clave): devuelve el valor asociado a la clave (o indica que no se encuentra)eliminar(clave): elimina la entrada
Inicialmente se tiene un trie vacío que consiste de un único nodo: la raíz.
- Para insertar un string a un trie, sólo hay que ir recorriéndolo desde la raíz creando los árcos y los nodos que hagan falta. En nuestro ejemplo anterior, si queremos agregar la palabra “TENAZ”, llegaremos hasta el nodo “TEN”, y luego vamos a tener que agregar dos arcos (y sus correspondientes nodos): A y Z para formar “TENAZ”.
- Para buscar un string, recorremos el trie desde la raíz hasta llegar al nodo tomando los arcos indicados por cada letra del string, en orden. Si en algún momento necesitamos tomar un arco que no existe, concluimos que el elemento buscado no se encuentra.
- Para borrar, hacemos una búsqueda, pero en lugar de borrar el nodo simplemente lo marcamos como “eliminado” y lo ignoramos en las subsecuentes búsquedas. Se debe recordar desmarcarlo si se hace una inserción.
Complejidad
Llamemos $n$ a la cantidad de elementos en la estructura y $k$ es la longitud de una clave.
Mientras que un map tiene una complejidad temporal $O(k\ \log n)$ para todas estas operaciones, un trie lo logra en $O(k)$: ¡es lineal!
Asímismo, la complejidad espacial también es lineal, $O(S)$ donde $S$ es la suma de las longitudes de todas las claves.
Implementación
Se sugiere fuertemente intentar programar un trie por cuenta propia sabiendo las ideas ya vistas.
Se proveen acá dos implementaciones de tries, una recursiva, y una iterativa.
De cualquier manera, la estructura propiamente dicha del trie es recursiva. ¿Por qué?
Al pensar recursivamente, se cometen menos errores.
La recursiva
- trie_recursivo.cpp
#include <iostream> #include <map> using namespace std; struct trie{ map<char, trie> m; // arcos bool final = false; // ¿una palabra termina en este nodo? void agregar(char *s){ if( *s ) m[*s].agregar(s+1); else final = true; } trie* buscar(char *s){ if( *s ){ if( m.count(*s) ) return m[*s].buscar(s+1); else return NULL; }else if( final ) return this; else return NULL; } void eliminar(char *s){ if( *s ) m[*s].eliminar(s+1); else final = false; } }; int main(){ trie t; t.agregar("CASA"); t.agregar("CAMA"); t.agregar("CAMARERO"); t.agregar("CASERO"); if( t.buscar("CAM") ) cout<<"CAM esta"<<endl; else cout<<"CAM no esta"<<endl; if( t.buscar("CAMA") ) cout<<"CAMA esta"<<endl; else cout<<"CAMA no esta"<<endl; t.eliminar("CAMA"); if( t.buscar("CAMA") ) cout<<"CAMA esta"<<endl; else cout<<"CAMA no esta"<<endl; if( t.buscar("CAMARERO") ) cout<<"CAMARERO esta"<<endl; else cout<<"CAMARERO no esta"<<endl; return 0; }
Esta implementación está buena como primera idea porque es simple. Sin embargo, realiza demasiadas llamadas a función, lo cual realentiza nuestro programa. También, al buscar un nodo, devuelve un puntero a él. Usar punteros puede no ser una idea muy estratégica en ámbitos de competencia. A continuación se provee de una implementación iterativa que es más rápida y no usa punteros.
La iterativa
- trie_iterativo.cpp
#include <iostream> #include <string> #include <cstring> #define forn(i, n) for(int i = 0; i < int(n); ++i) using namespace std; const int maxn = 1000; // maxima cantidad de nodos int proximo_libre; int sig[maxn][26]; // arcos (en este caso sólo letras mayusculas) bool final[maxn]; // ¿una palabra termina en este nodo? void agregar(const string &s, int raiz = 0){ int actual = raiz; forn(i, s.size()){ int letra = s[i] - 'A'; if( sig[ actual ][ letra ] == -1 ) sig[ actual ][ letra ] = proximo_libre++; actual = sig[ actual ][ letra ]; } final[ actual ] = true; } int buscar(const string &s, int raiz = 0){ int actual = raiz; forn(i, s.size()){ int letra = s[i] - 'A'; if( sig[ actual ][ letra ] == -1 ) return -1; actual = sig[ actual ][ letra ]; } if( final[ actual ] ) return actual; else return -1; } void eliminar(const string &s, int raiz = 0){ int actual = raiz; forn(i, s.size()){ int letra = s[i] - 'A'; if( sig[ actual ][ letra ] == -1 ) return; actual = sig[ actual ][ letra ]; } final[ actual ] = false; } int main(){ memset(sig, -1, sizeof(sig)); // seteamos en -1 todos los arcos para indicar que no existen agregar("CASA"); agregar("CAMA"); agregar("CAMARERO"); agregar("CASERO"); int trie2 = proximo_libre++; agregar("CAMA", trie2); if( buscar("CAM") != -1 ) cout<<"CAM esta"<<endl; else cout<<"CAM no esta"<<endl; if( buscar("CAMA") != -1 ) cout<<"CAMA esta"<<endl; else cout<<"CAMA no esta"<<endl; eliminar("CAMA"); if( buscar("CAMA") != -1 ) cout<<"CAMA esta"<<endl; else cout<<"CAMA no esta"<<endl; if( buscar("CAMARERO") != -1 ) cout<<"CAMARERO esta"<<endl; else cout<<"CAMARERO no esta"<<endl; cout<<"En el trie 2:"<<endl; if( buscar("CAMA", trie2) != -1 ) cout<<"CAMA esta"<<endl; else cout<<"CAMA no esta"<<endl; if( buscar("CAMARERO", trie2) != -1 ) cout<<"CAMARERO esta"<<endl; else cout<<"CAMARERO no esta"<<endl; return 0; }
Un detalle para tener en cuenta es que para no tener que lidiar con memoria dinámica, reservamos estáticamente la memoria para todos los nodos posibles. De esta manera, cada nodo está identificado con un entero y ya no tenemos que devolver punteros. Más aún, esto no nos imposibilita usar varios tries en simultáneo: cada vez que se desee crear uno nuevo, se reserva un nodo para la raíz.
Mejoras
String sorting en tiempo lineal
Esto no es una mejora per se, pero muestra muy bien cómo se organizan las palabras dentro de un trie.
Tomemos la lista de palabras que se quiere ordenar e ingresémosla en un trie. Un recorrido DFS que visita los arcos en orden alfabético recorrerá las palabras lexicográficamente. Recorrer los arcos en sentido inverso para ordenar las palabras en sentido contrario.
Contador de prefijos
Esta mejora es muy sencilla pero muy poderosa, consiste en agregar un contador a cada nodo. Cada vez que se inserte una palabra que pase por el nodo, se aumenta el contador en 1. Ahora podemos escribir una función cuentaPrefijos( s ) que devuelve la cantidad de palabras que comienzan con s.
agregar("CASA");
agregar("CAMA");
agregar("CAMARERO");
agregar("CASERO");
cuentaPrefijos("CA") --> 4
cuentaPrefijos("CASE") --> 1
cuentaPrefijos("CASO") --> 0
Puntero al siguiente nodo final
Una vez construido el trie, un recorrido postorden en orden inverso nos permite calcular en una sola pasada para cada nodo cuál es el siguiente nodo final. Podemos mejorar así nuestra estructura trie agregando un campo sig a cada nodo. A continuación un pseudocódigo:
nodo calcularSiguiente(nodo yo, nodo s){
for(cada hijo en orden inverso)
s = calcularSiguiente(hijo, s);
yo.sig = s;
if( yo.final ) return yo
else return yo.sig;
}
y computamos los siguientes para todo el trie así: calcularSiguiente(raiz, NULL).
Trie de sufijos
- Ejercicio: Dibujar el trie que contiene la palabra “CAMISA”, y dibujar otro trie que contiene las palabras “CAMISA”, “CAMIS”, “CAMI”, “CAM”, “CA”, y “C”.
Ambos son el mismo trie, ¿no? Esto es porque al ingresar una palabra, también ingresamos todos sus prefijos. La única diferencia es que en el primer caso, sólo un nodo es final, mientras que en el segundo todos los nodos son finales. Podemos escribir una función agregarPrefijos que sea exactamente igual a agregar pero que vaya marcando todos los nodos como finales. ¡Y mantenemos la complejidad $O(k)$!
Por lo tanto, si queremos insertar todos los substrings de un texto de longitud $T$, sólo necesitamos agregarPrefijos de sus $T$ sufijos, que tarda $O(T^2)$ en total. Una vez construido este trie de sufijos, muchas operaciones pueden realizarse eficientemente:
Cantidad de apariciones de un string $S$ en $O(S)$
Si tenemos un string $S$, la cantidad de apariciones en el texto es simplemente cuentaPrefijos(S) en el trie de sufijos.
Adicionalmente, si en cada inserción además de marcar el nodo como final, guardamos el índice del substring y un puntero al siguiente nodo final, un recorrido de los nodos finales del subtrie cuya raiz se corresponde a $S$ nos arrojará todos los índices en los cuales aparece $S$ con costo adicional $O(A)$ donde $A$ es la cantidad de apariciones.
Substring más largo que se repite al menos $K$ veces en $O(T^2)$
Consideremos un recorrido DFS en el trie de sufijos. Un nodo de profundidad $l$ se corresponde con un string de largo $l$, y el contador de un nodo indica cuántas veces aparece la palabra correspondiente a dicho nodo en el trie. Por lo que recorreremos el trie buscando un nodo de profundidad máxima cuyo contador sea mayor o igual a $K$.
Substring más largo que aparezca en al menos $K$ de $N$ palabras, en tiempo cuadrático
Supongamos que tenemos una lista de $n$ palabras de longitud $s_i$. Construyamos un trie de sufijos común a todas las palabras, pero manteniendo con cuidado un contador en cada nodo que indica a cuántas palabras distintas corresponde ese nodo. Es decir, si tengo dos palabras: “PAPA” y “PALO”, el nodo correspondiente a “PA” tiene contador 2 -y no 3- ya que aunque aparece 3 veces, aparece sólo en 2 palabras distintas. La respuesta a nuestro problema está dada por el nodo más profundo cuyo contador sea al menos $K$.
El costo de construcción de este trie de prefijos común es $O(s_1^2 + \dots + s_n^2)$, por lo que es cuadrático.
Palabra más cercana
Supongamos el siguiente problema: Tenemos dos palabras, de longitudes $N$ y $M$ respectivamente. Su distancia es la mínima cantidad de inerciones, reemplazos y eliminaciones para convertir la primera en la segunda. Por ejemplo, la distancia entre “PERRO” y “ERDOS” es 3: una inserción (S), un reemplazo (R->D) y un borrado (P).
Cmo ya es sabido, la solución a este problema puede encontrarse mediante Programación Dinámica en tiempo $O(NM)$ rellenando una tabla.
| E | R | D | O | S | ||
|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | |
| P | 1 | 1 | 2 | 3 | 4 | 5 |
| E | 2 | 1 | 2 | 3 | 4 | 5 |
| R | 3 | 2 | 1 | 2 | 3 | 4 |
| R | 4 | 3 | 2 | 2 | 3 | 4 |
| O | 5 | 4 | 5 | 3 | 2 | 3 |
Pero qué pasaría si en lugar de querer calcular la distancia entre dos palabras, quisiera -dada una palabra fija $w$- encontrar otra palabra $w'$ perteneciente a un diccionario de tamaño $N$ cuya distancia $d(w,w')$ sea mínima?
Repetir el algoritmo para cada palabra no sería muy útil, ya que estaríamos recalculando muchas veces la misma información. Consideremos que ahora, en lugar de comparar con “PERRO”, queremos comparar con “PERROS”. ¡La tabla que ya tengo armada me sirve! sólo tengo que agregar una fila adicional. Los tries son perfectos para esto ya que me dicen exactamente los prefijos en común entre varias palabras, que se reflejan en filas de mi tabla que no tengo que volver a recalcular.
Puntero al padre
Consiste en guardar en cada nodo, cuál es su padre. Es una mejora muy simple agregando una línea extra a la función agregar. Esto nos permite movernos en cualquier dirección dentro del trie, lo cual nos será útil en la siguiente mejora:
Trie de cosas locas
En lugar de etiquetar los arcos con letras, se los puede etiquetar con cualquier otra cosa, por ejemplo: enteros. Si la cantidad de etiquetas distintas -llamémosla $E$- no está acotada, quizás haya que usar un map<int, trie> a costa de un $O(\log E)$ adicional. Como la cantidad de arcos que salen de un nodo no suele ser muy grande, algunas veces es más rápido guardar un vector o un array pequño de arcos y hacer una búsqueda lineal.
Stack persistente
Una estructura de datos persistente es, hablando mal y pronto, una estructura donde cada operación devuelve una copia nueva en lugar de modificar la anterior. De esta manera, ambas versiones son totalmente independientes y uno puede optar seguir realizando operaciones en cualquiera de ellas.
Una pila (stack) es una estructura de datos que permite las siguientes operaciones:
push(x): apila x en el tope de la pilatop(): devuelve el valor del tope de la pilapop(): desapila el elemento del tope de la pila
Así, una pila persistente es una pila donde cada operación (excepto quizás top que no hace nada) devuelve una nueva instancia de la pila.
Una pila de enteros persistente se corresponde con un nodo s de un trie etiquetado con enteros:
push_persistente(s, x): insertar un arco y un nodos' con etiqueta x, luego la nueva pila ess'.top(): es el valor almacenado enspop_persitente(s): seas' el padre des, la nueva pila ess'.
¡Estas operaciones persistentes siguen siendo constantes! 1) $O(1)$
Trie binario
Cuando pensamos en tries, pensamos en strings. Sin embargo, no hay que olvidarse que los enteros pueden pensarse también como strings binarios al mirar su representación en base 2. Así, 13 = “0...01101” con tantos 0 a la izquierda como queramos. Es útil como estructura de diccionario porque este tipo de trie siempre está balanceado, su altura es $O($cantidad de bits de las claves$)$.
Problemas
OIA Nacional 2014 N2 - Verificando contraseñas
Dado un diccionario de palabras, indicar para cada una cuántas otras palabras del diccionario son prefijos de ella.
OIA Selectivo 2009 - Formando equipo
Se tiene un diccionario con palabras. La afinidad $a$ de un subconjunto $S$ de palabras se define como $a =|S|\cdot p^2$ donde $|S|$ es la cantidad de palabras de $S$ y $p$ es el largo del prefijo común más largo a todas las palabras de $S$.
Hallar la afinidad máxima posible y el prefijo común más largo asociado.
UVa 12526 - Cellphone Typing
Se tiene un diccionario de palabras y un teléfono viejo con predicción de palabra. El sistema de predicción es simple:
- El sistema nunca adivina la primer leta de una palabra, se debe presionar una tecla manualmente
- Si se ingresan letras $c_1c_2..c_r$ y todas las palabras que comienzan por $c_1c_2..c_r$ continúan con $c_{r+1}c_{r+2}..c_n$, entonces el sistema autocompleta la palabra a $c_1c_2..c_n$. Por ejemplo, si el diccionario es: “CAMARERO”, “CAMARA”, y “PLAYA”, y el usuario ingresa “C”, el sistema automáticamente completa a “CAMAR”.
Se quiere saber cuántas pulsasiones de teclas en promedio hay que apretar para escribir alguna palabra del diccionario. En nuestro pequeño ejemplo, 1.66 = (2 + 2 + 1).
IOI 2008 - Type Printer
Se dispone de una máquina de imprenta antigua que funciona poniendo manualmente piezas metálicas con letras para formar palabras. Una vez formada una palabra, se presiona contra un papel (cual sello) para imprimir. La imprenta permite realizar alguna de las siguientes operaciones:
- agregar una letra metálica al final de la palabra actual
- eliminar una letra metálica del final de la palabra actual
- imprimir la palabra formada por las piezas actualmente en la máquina
Se dispone de un diccionario de palabras que se quiere imprimir al completo (no importa el orden). Inicialmente la imprenta está vacía. Como cada operación demora su tiempo, se quiere saber la menor cantidad de operaciones en las cuales es posible realizar la tarea.
IOI 2012 - Scrivener
Se dispone de una imprenta cangrejo: una máquina que soporta los siguientes comandos:
- agregar(L) : agrega una L metálica al final de la palabra actual
- deshacer(U) : deshace los últimos U comandos (inclusive los deshacer)
Adicionalmente, también soporta la siguiente operación:
- imprimir(P) : imprime la p-ésima letra de la palabra actual. Esta operación no es un comando y por ende es ignorada por el comando deshacer
| Operación | Devuelve | Palabra actual |
|---|---|---|
| agregar( a ) | a | |
| agregar( b ) | ab | |
| imprimir( 1 ) | b | ab |
| agregar( d ) | abd | |
| deshacer( 2 ) | a | |
| deshacer( 1 ) | abd | |
| imprimir( 2 ) | d | abd |
| agregar( e ) | abde | |
| deshacer( 1 ) | abd | |
| deshacer( 5 ) | ab | |
| agregar( c ) | abc | |
| imprimir( 2 ) | c | abc |
| deshacer( 2 ) | abd | |
| imprimir( 2 ) | d | abd |
Se te pide que hagas una simulación por software de la imprenta cangrejo.
Codeforces Round #260 - A Lot of Games
Se tiene un listado de palabras. Dos personas, A y B juegan al siguiente juego sobre un renglón de una hoja de papel:
- al principio, el renglón está vacío
- el juego es por turnos, comienza A
- cada jugada consiste en agregar una letra al final de la palabra, la jugada es válida si la palabra formada es un prefijo de alguna de las palabras del listado.
- aquel que no pueda jugar, pierde
Si ambos jugadores juegan óptimamente, ¿quién gana?
tries y xor
max xor pair from set max xor subarray number of subarrays with xor less than K DP + trie