Herramientas de usuario
¡Esta es una revisión vieja del documento!
Tabla de Contenidos
Introducción
A veces, un programa debe leer una cadena de caracteres y “entenderla”: la cadena describe algo, que se forma con ciertas reglas, y hay que interpretar eso en el programa.
Un ejemplo muy sencillo sería por ejemplo, si queremos hacer una calculadora básica, y tenemos en un string un texto con números separados por “+”, como puede ser 123+43+23. Cuando recibimos este string, en realidad lo que querríamos tener sería un arreglo de 3 enteros, cuyos valores como int sean 123, 43 y 23, de modo que podamos sumarlos con el + y obtener el resultado del cálculo pedido: 189.
La dificultad entonces es que justamente, tenemos esta expresión dada como texto, como cadena de caracteres, y queremos entenderla para conseguir sus partes y su estructura para poder trabajar con ella en el programa. A este proceso de pasar del string a una representación de la estructura expresada por ese string, le llamaremos parsing.1)
Gramáticas
En general, los textos permitidos se pueden especificar utilizando una gramática. Una gramática es una serie de reglas, que especifican cómo son los textos válidos, indicando de alguna manera la relación que debe haber entre las partes que forman el texto, tal y como la gramática de los lenguajes naturales (castellano, inglés, latín, chino, etc) determina las reglas que indican las relaciones que debe haber entre las palabras que forman un texto válido.
Por ejemplo, no es válido poner “La casa es rojo”, porque una regla indica que un sustantivo femenino debe utilizarse con un adjetivo femenino.
Del ejemplo anterior, podemos rescatar que las gramáticas clasifican las distintas partes del texto, dándole un cierto “tipo” a cada una: en el ejemplo, hablamos de los “tipos” sustantivo y adjetivo, que son posibles partes del texto, pero que pueden tener reglas diferentes.
Gramáticas BNF
Una forma muy práctica de dar una gramática formal, para utilizar en computación, es la denominada forma de Backus–Naur.
Lo que se hace es simplemente indicar, para cada “tipo” o “elemento” de la gramática, las distintas opciones de cómo es posible formarlo utilizando otros elementos. Estas opciones se separan con el símbolo |
Veamos un ejemplo:
<expresion> ::= <numero> | <numero> + <expresion>
<numero> ::= <digito> | <digito> <numero>
<digito> ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
Esta gramática en BNF se corresponde con las expresiones de la “calculadora” de ejemplo mencionada anterior: Por ejemplo, podemos tomar como válido el texto 123+43+23 porque:
- 3 es un número porque es un dígito (primera regla de <numero>)
- 23 es un número porque es un dígito y luego un número (segunda regla de <numero>, junto a lo que ya vimos de que 3 es un <numero> válido)
- De la misma forma, 123 es un número, pues es un dígito y luego un número.
- De la misma forma podemos concluir que 43 y 23 son números.
- 23 es una expresión, porque usando la primera regla, tenemos que un número es una expresión
- 43+23 es una <expresion> válida, porque usando la segunda regla, como 43 es número y 23 es expresión, tenemos que 43+23 es de la forma <numero> + <expresion>
- Finalmente, 123+43+23 es una expresión válida, porque por la segunda regla, como ya sabemos que 43+23 es una expresión y 123 es un número, tenemos que 123+43+23 es un número, seguido de un +, seguido de una expresión, como pide la regla.
El proceso que hemos realizado en este ejemplo, de descomponer el string de 9 caracteres dado en sus componentes de acuerdo a las reglas de la gramática, es lo que se denomina parsing o análisis sintáctico. En general, el resultado de todo el proceso anterior puede resumirse más gráficamente mediante un árbol de parsing, que indica cómo se va realizando la descomposición. Para el ejemplo anterior, el árbol de parsing sería:
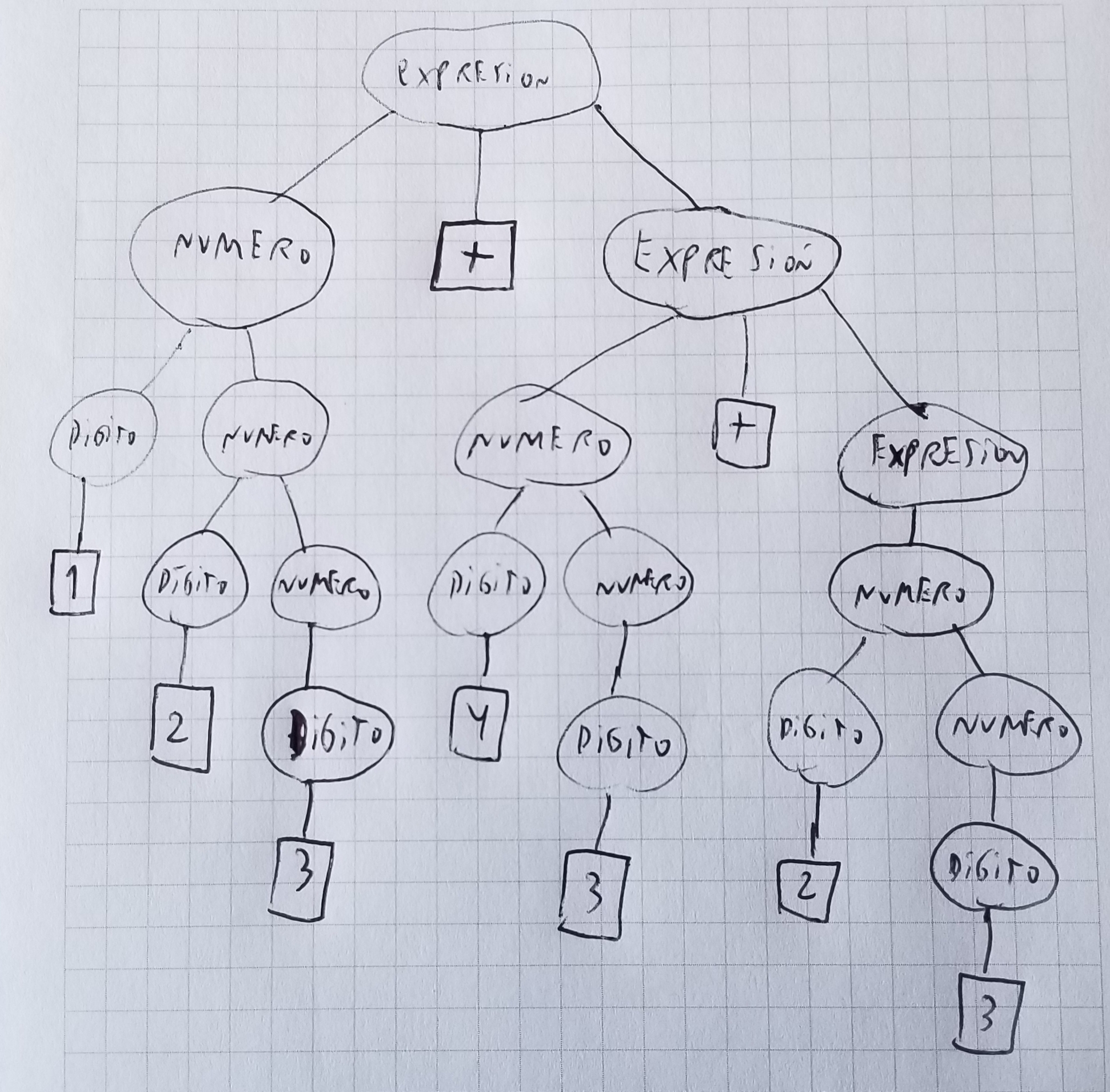
De esta manera, en general se considera que el parsing es el proceso de obtener el árbol de parsing a partir del texto. O al menos, al proceso de recorrer el árbol implícitamente durante el proceso de parsing del texto. Al programa o algoritmo que realiza el parsing, se lo llama parser.2)
Dado un texto y una gramática, el árbol de parsing puede no ser único: cuando la gramática permite varios árboles diferentes para un mismo texto, la gramática es ambigua. En general, es más difícil hacer parsing para gramáticas ambiguas. La gramática que dimos como ejemplo no es ambigua, pero si por ejemplo agregáramos la regla adicional <expresion> + <numero> (que es como la que ya teníamos pero en otro orden), la gramática se vuelve ambigua, pues según cuál de las dos reglas vamos usando, quedan árboles con forma diferente.
Parser recursivo descendente predictivo [EL IMPORTANTE]
OBSERVACIÓN IMPORTANTE: Prácticamente todas las veces que tengamos que implementar un parser en una competencia de programación algorítmica tipo OIA/IOI/ICPC, lo más conveniente será utilizar un parser recursivo descendente predictivo.3)
La idea para este parser es leer todo el texto en una sola pasada de izquierda a derecha, pero armar el árbol de parsing mediante recursión. De esta manera, tendremos una función por cada tipo de elemento de la gramática. En el ejemplo anterior, tendríamos una función para expresión, una para número y una para dígito. Además, hay una variable global que indica la siguiente posición del texto que hay que leer (y este contador va avanzando a medida que vamos “consumiendo” texto).
La idea es que, de acuerdo a la regla que usemos, consumir el texto de un cierto elemento se descompone en consumir el texto de otros. Por ejemplo para consumir una expresión, si usamos la segunda regla, tendremos que primero consumir un número, luego consumir el símbolo +, y finalmente consumir una expresión.
La clave es la parte de predictivo: En cada paso, hay que saber cuál de las reglas utilizar. Por ejemplo, en la función que se encarga de consumir una expresión, hay que saber si vamos a usar la primera regla o la segunda. Esta predicción la hacemos considerando las propiedades de la gramática que estemos trabajando, mirando el texto que sigue en el string, etc, y variará en cada caso. En los casos más simples, basta mirar el siguiente caracter para predecir qué regla hay que aplicar, pero a veces puede hacer falta mirar más adelante.
Juntando todas estas ideas, un ejemplo para la gramática de más arriba, que sería un parser básico que solamente dice si el texto está bien (respeta la gramática) o no, sería:
Una desventaja del parser recursivo descendente tal cual lo planteamos es que no puede manejar una gramática que tenga ninguna forma de recursión a izquierda (es decir, una regla como X ::= X Y Z, porque para usarla X tendría que llamar a X sin haber consumido nada, así que el programa cuelga). La solución a esto muchas veces es plantear un while para consumir todas esas repeticiones (porque en general esas construcciones en la gramática se usan para indicar “varias copias de ...”, y podemos hacerlo con while). Otras veces se puede replantear la gramática para que no tenga recursión a izquierda (por ejemplo, si se puede elegir el orden, utilizar recursión a derecha).
Parser recursivo descendente con backtracking (no predictivo)
Este parser permite trabajar con gramáticas ambiguas, y en ese caso se puede utilizar para encontrar y enumerar todos los árboles de parsing posibles. Pero tiene el gran defecto de tener en la mayoría de los casos una complejidad exponencial en la longitud del texto. En competencias de programación, si de verdad necesitamos un parser, virtualmente siempre podremos utilizar un parser predictivo, por lo cual tener que implementar un recursivo descendente para gramáticas en general es algo sumamente inusual.
NOTA: Este parser no se puede utilizar si la gramática tiene recursión a izquierda, pues en ese caso nunca termina.
PENDING: Explicar el parser. 
Como comentario final, existen algoritmos polinomiales que permiten parsear cualquier gramática BNF, como son el algoritmo de Earley y el CYK (de Cocke-Younger-Kasami). Si bien el planteo es diferente, en el fondo son algoritmos de programación dinámica que plantean estados muy similares a los del backtracking del parser recursivo descendente que vimos, pero al utilizar memoización, se evita recalcular un mismo estado muchas veces.
Herramientas de la página
