Tabla de Contenidos
Introducción
A veces, un programa debe leer una cadena de caracteres y “entenderla”: la cadena describe algo, que se forma con ciertas reglas, y hay que interpretar eso en el programa.
Un ejemplo muy sencillo sería por ejemplo, si queremos hacer una calculadora básica, y tenemos en un string un texto con números separados por “+”, como puede ser 123+43+23. Cuando recibimos este string, en realidad lo que querríamos tener sería un arreglo de 3 enteros, cuyos valores como int sean 123, 43 y 23, de modo que podamos sumarlos con el + y obtener el resultado del cálculo pedido: 189.
La dificultad entonces es que justamente, tenemos esta expresión dada como texto, como cadena de caracteres, y queremos entenderla para conseguir sus partes y su estructura para poder trabajar con ella en el programa. A este proceso de pasar del string a una representación de la estructura expresada por ese string, le llamaremos parsing.1)
Gramáticas
En general, los textos permitidos se pueden especificar utilizando una gramática. Una gramática es una serie de reglas, que especifican cómo son los textos válidos, indicando de alguna manera la relación que debe haber entre las partes que forman el texto, tal y como la gramática de los lenguajes naturales (castellano, inglés, latín, chino, etc) determina las reglas que indican las relaciones que debe haber entre las palabras que forman un texto válido.
Por ejemplo, no es válido poner “La casa es rojo”, porque una regla indica que un sustantivo femenino debe utilizarse con un adjetivo femenino.
Del ejemplo anterior, podemos rescatar que las gramáticas clasifican las distintas partes del texto, dándole un cierto “tipo” a cada una: en el ejemplo, hablamos de los “tipos” sustantivo y adjetivo, que son posibles partes del texto, pero que pueden tener reglas diferentes.
Gramáticas BNF
Una forma muy práctica de dar una gramática formal, para utilizar en computación, es la denominada forma de Backus–Naur.
Lo que se hace es simplemente indicar, para cada “tipo” o “elemento” de la gramática, las distintas opciones de cómo es posible formarlo utilizando otros elementos. Estas opciones se separan con el símbolo |
Veamos un ejemplo:
<expresion> ::= <numero> | <numero> + <expresion>
<numero> ::= <digito> | <digito> <numero>
<digito> ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
Esta gramática en BNF se corresponde con las expresiones de la “calculadora” de ejemplo mencionada anterior: Por ejemplo, podemos tomar como válido el texto 123+43+23 porque:
- 3 es un número porque es un dígito (primera regla de <numero>)
- 23 es un número porque es un dígito y luego un número (segunda regla de <numero>, junto a lo que ya vimos de que 3 es un <numero> válido)
- De la misma forma, 123 es un número, pues es un dígito y luego un número.
- De la misma forma podemos concluir que 43 y 23 son números.
- 23 es una expresión, porque usando la primera regla, tenemos que un número es una expresión
- 43+23 es una <expresion> válida, porque usando la segunda regla, como 43 es número y 23 es expresión, tenemos que 43+23 es de la forma <numero> + <expresion>
- Finalmente, 123+43+23 es una expresión válida, porque por la segunda regla, como ya sabemos que 43+23 es una expresión y 123 es un número, tenemos que 123+43+23 es un número, seguido de un +, seguido de una expresión, como pide la regla.
El proceso que hemos realizado en este ejemplo, de descomponer el string de 9 caracteres dado en sus componentes de acuerdo a las reglas de la gramática, es lo que se denomina parsing o análisis sintáctico. En general, el resultado de todo el proceso anterior puede resumirse más gráficamente mediante un árbol de parsing, que indica cómo se va realizando la descomposición. Para el ejemplo anterior, el árbol de parsing sería:
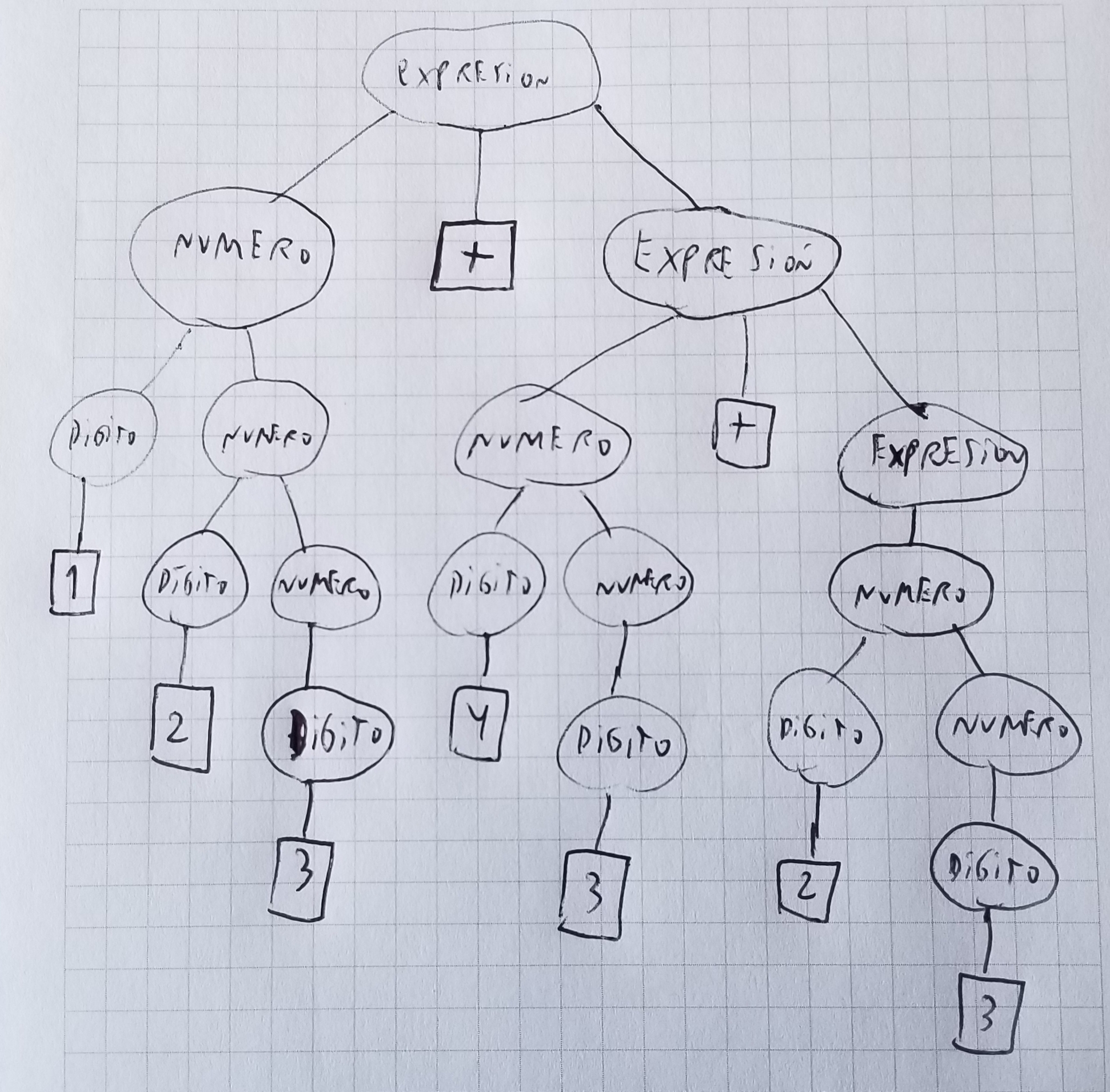
De esta manera, en general se considera que el parsing es el proceso de obtener el árbol de parsing a partir del texto. O al menos, al proceso de recorrer el árbol implícitamente durante el proceso de parsing del texto. Al programa o algoritmo que realiza el parsing, se lo llama parser.2)
Dado un texto y una gramática, el árbol de parsing puede no ser único: cuando la gramática permite varios árboles diferentes para un mismo texto, la gramática es ambigua. En general, es más difícil hacer parsing para gramáticas ambiguas. La gramática que dimos como ejemplo no es ambigua, pero si por ejemplo agregáramos la regla adicional <expresion> + <numero> (que es como la que ya teníamos pero en otro orden), la gramática se vuelve ambigua, pues según cuál de las dos reglas vamos usando, quedan árboles con forma diferente.
Parser recursivo descendente predictivo [EL IMPORTANTE]
OBSERVACIÓN IMPORTANTE: Prácticamente todas las veces que tengamos que implementar un parser en una competencia de programación algorítmica tipo OIA/IOI/ICPC, lo más conveniente será utilizar un parser recursivo descendente predictivo.3)
La idea para este parser es leer todo el texto en una sola pasada de izquierda a derecha, pero armar el árbol de parsing mediante recursión. De esta manera, tendremos una función por cada tipo de elemento de la gramática. En el ejemplo anterior, tendríamos una función para expresión, una para número y una para dígito. Además, hay una variable global que indica la siguiente posición del texto que hay que leer (y este contador va avanzando a medida que vamos “consumiendo” texto).
La idea es que, de acuerdo a la regla que usemos, consumir el texto de un cierto elemento se descompone en consumir el texto de otros. Por ejemplo para consumir una expresión, si usamos la segunda regla, tendremos que primero consumir un número, luego consumir el símbolo +, y finalmente consumir una expresión.
La clave es la parte de predictivo: En cada paso, hay que saber cuál de las reglas utilizar. Por ejemplo, en la función que se encarga de consumir una expresión, hay que saber si vamos a usar la primera regla o la segunda. Esta predicción la hacemos considerando las propiedades de la gramática que estemos trabajando, mirando el texto que sigue en el string, etc, y variará en cada caso. En los casos más simples, basta mirar el siguiente caracter para predecir qué regla hay que aplicar, pero a veces puede hacer falta mirar más adelante.
Juntando todas estas ideas, un ejemplo para la gramática de más arriba, que sería un parser básico que solamente dice si el texto está bien (respeta la gramática) o no, sería:
#include <iostream> using namespace std; string texto = "123+43+23$"; // Es comodo poner un $ especial al final, para evitar chequeos de fuera de rango int posicion; bool quedaAlgunMas() { for (int i = posicion; i < int(texto.size()); i++) if (texto[i] == '+') return true; return false; } bool consumir(char c) { if (texto[posicion] != c) return false; posicion++; return true; } bool noEsDigito(char c) { return c < '0' || c > '9'; } // Declaramos primero todas las funciones de la gramatica: // En este caso no hace falta, pero muchas veces si, porque se // llaman en ciclo y entonces no hay forma de ordenarlas en el archivo // sin declararlas primero. bool expresion(); bool numero(); bool digito(); bool expresion() { if (quedaAlgunMas()) { // Prediccion para este caso // Si queda algun mas, aplicamos la regla 2 if (!numero()) return false; if (!consumir('+')) return false; return expresion(); } else { // Sino, la regla 1 return numero(); } } bool numero() { // El primer chequeo en este caso es solamente para evitar evaluar posicion+1 si texto[posicion] == '$' // Por ejemplo eso pasaria al intentar parsear "123+" [incompleto]. Querriamos que ese texto de "false", // no tener un error fuera de rango. // Se podria sacar afuera como su propio chequeo aparte, pero lo dejamos asi para que el parser // quede escrito mas "mecanico", enfatizando que salvo la condicion para la prediccion, // todo el resto del codigo se sigue en forma 100% automatica de la gramatica. if (noEsDigito(texto[posicion]) || noEsDigito(texto[posicion+1])) { // Prediccion para este caso // Regla 1 return digito(); } else { // Regla 2 if (!digito()) return false; return numero(); } } bool digito() { // Estrictamente como esta escrita la gramatica, // tenemos 10 reglas y podriamos verificar una por una // En este caso como siempre es igual, las resumimos en codigo if (noEsDigito(texto[posicion])) return false; posicion++; return true; } int main() { posicion = 0; // Siempre debe empezar en 0 bool parseOk = expresion(); if (parseOk && texto[posicion] == '$') // Si no pedimos texto[posicion] == '$', puede haber dado ok un prefijo, pero no se consumio todo. cout << "OK!" << endl; else cout << "ERROR!" << endl; }
Ejecutando el ejemplo anterior cambiando el string, se puede ver que indica error exactamente cuando la cadena no respeta las reglas. Por ejemplo para
string texto = “$”string texto = “123+$”string texto = “123++57$”string texto = “123+21×3$”
Indica error.
Notar que las llamadas recursivas que se van haciendo copian exactamente el árbol de parsing. Esto es muy útil, en particular si quisiéramos generar el árbol de parsing podríamos hacerlo durante la misma recursión: cada función en lugar de solo un bool, devolvería el subárbol calculado, y entonces como resultado de una función de parsing se retornaría un nodo raíz al cual se adicionan en orden los nodos raíces de los subárboles devueltos por las llamadas hijo.
Sin embargo, en muchos casos es más cómodo “utilizar” el árbol directamente en la recursión, en lugar de construirlo explícitamente para luego procesarlo. Por ejemplo, en este ejemplo, podríamos ir calculando el resultado de la cuenta, y obtener un programa que hace la cuenta. Para esto hay que saber qué retornar en cada caso, a partir de lo que retornan los hijos. En nuestro ejemplo:
- Para una expresión, podríamos retornar la suma de lo que devuelvan los hijos (o directamente lo que devuelve el único hijo, si se usa la regla 1)
- Para un número, podemos calcular el resultado de agregar un dígito a la izquierda, y aplicar eso a los hijos que tenemos.
- Para el caso de un dígito, se puede pasar directamente el char a entero.
El código que calcularía esto es:
#include <iostream> using namespace std; string texto = "123+43+2$"; // Es comodo poner un $ especial al final, para evitar chequeos de fuera de rango int posicion; bool quedaAlgunMas() { for (int i = posicion; i < int(texto.size()); i++) if (texto[i] == '+') return true; return false; } void consumir(char c) { if (texto[posicion] != c) throw "ERROR"; posicion++; } bool noEsDigito(char c) { return c < '0' || c > '9'; } // Declaramos primero todas las funciones de la gramatica: // En este caso no hace falta, pero muchas veces si, porque se // llaman en ciclo y entonces no hay forma de ordenarlas en el archivo // sin declararlas primero. int expresion(); string numero(); // Usamos string para los numeros en este caso, que es mas ineficiente, porque es dificil agregar por izquierda. // Agregar por derecha es simplemente "10*num + d". // Eso indica que en este problema particular, // hubiera sido mejor cambiar la gramatica para que la regla sea "<num> <digito>" en lugar de "<digito> <num>" char digito(); int expresion() { if (quedaAlgunMas()) { // Prediccion para este caso // Si queda algun mas, aplicamos la regla 2 string num = numero(); consumir('+'); int e = expresion(); return stoi(num) + e; } else { // Sino, la regla 1 return stoi(numero()); } } string numero() { // El primer chequeo en este caso es solamente para evitar evaluar posicion+1 si texto[posicion] == '$' // Por ejemplo eso pasaria al intentar parsear "123+" [incompleto]. Querriamos que ese texto de "false", // no tener un error fuera de rango. // Se podria sacar afuera como su propio chequeo aparte, pero lo dejamos asi para que el parser // quede escrito mas "mecanico", enfatizando que salvo la condicion para la prediccion, // todo el resto del codigo se sigue en forma 100% automatica de la gramatica. if (noEsDigito(texto[posicion]) || noEsDigito(texto[posicion+1])) { // Prediccion para este caso // Regla 1 return string(1,digito()); } else { // Regla 2 char d = digito(); string num = numero(); return d + num; } } char digito() { // Estrictamente como esta escrita la gramatica, // tenemos 10 reglas y podriamos verificar una por una // En este caso como siempre es igual, las resumimos en codigo if (noEsDigito(texto[posicion])) throw "ERROR"; char d = texto[posicion]; posicion++; return d; } int main() { try { posicion = 0; // Siempre debe empezar en 0 int result = expresion(); if (texto[posicion] != '$') // Si no pedimos texto[posicion] == '$', puede haber dado ok un prefijo, pero no se consumio todo. throw "ERROR"; cout << "OK! Resultado : " << result << endl; } catch (...) { cout << "ERROR!" << endl; } }
Este ejemplo muestra otra técnica posible para la detección de los errores en parsing: en lugar de retornar un valor especial destacado y tener que chequear error todo el tiempo, como los errores abortan todo el parsing completo, se usa un “throw” que lanza excepción, y todo el código del parser está rodeado de un try catch, de modo que en cuanto salta un error, termina toda la recursión automáticamente y el código pasa al caso error.
Notar que en algunos casos, el problema nos garantiza que no hay casos de ERROR, y podemos omitir los chequeos de error en el parsing, asumiendo que el parsing sera correcto. Por ejemplo si el problema pidiera implementar una calculadora para expresiones que siguen cierta gramatica, y nos garantizan que el input siempre va a cumplir ese formato.
La gramática que usamos de ejemplo era muy sencilla, y seguramente se podía haber creado un parser con for directamente leyendo los enteros y sumando, pero la misma técnica general aplica al parsing de cualquier gramática. Por ejemplo, si en nuestra “calculadora” pudiéramos usar * además de +, y hubiera paréntesis y corchetes que por regla debemos verificar que matcheen, con una gramática un poco cambiada podríamos aplicar estas técnicas de la misma manera exacta, mientras que adaptar la solución adhoc con for se vuelve muy engorroso por comparación.
Una desventaja del parser recursivo descendente tal cual lo planteamos es que no puede manejar una gramática que tenga ninguna forma de recursión a izquierda (es decir, una regla como X ::= X Y Z, porque para usarla X tendría que llamar a X sin haber consumido nada, así que el programa cuelga). La solución a esto muchas veces es plantear un while para consumir todas esas repeticiones (porque en general esas construcciones en la gramática se usan para indicar “varias copias de ...”, y podemos hacerlo con while). Otras veces se puede replantear la gramática para que no tenga recursión a izquierda (por ejemplo, si se puede elegir el orden, utilizar recursión a derecha).
Parser recursivo descendente con backtracking (no predictivo)
Este parser permite trabajar con gramáticas ambiguas, y en ese caso se puede utilizar para encontrar y enumerar todos los árboles de parsing posibles. Pero tiene el gran defecto de tener en la mayoría de los casos una complejidad exponencial en la longitud del texto. En competencias de programación, si de verdad necesitamos un parser, virtualmente siempre podremos utilizar un parser predictivo, por lo cual tener que implementar un recursivo descendente para gramáticas en general es algo sumamente inusual.
NOTA: A diferencia del parser predictivo, este parser general por backtracking sin predicción no se puede utilizar si la gramática tiene recursión a izquierda, pues en ese caso nunca termina. Un ejemplo de recursión a izquierda sería una regla del estilo <numero> ::= <numero> <digito>, a diferencia de <numero> ::= <digito> <numero> que sería recursión a derecha.
Por ejemplo, para la gramatica
<X> ::= a <X> a | a <X> a <X> | b <X> | b
Que tiene solamente un tipo de elemento X, podríamos generar el siguiente parser recursivo descendente:
#include <iostream> #include <string> #include <vector> using namespace std; string texto; // Devuelve todos los posibles end, al parsear un X empezando en posicion vector<int> X(int posicion) { vector<int> ret; // Regla aXa if (texto[posicion] == 'a') { for (int pos2 : X(posicion+1)) { if (texto[pos2] == 'a') ret.push_back(pos2+1); } } // Regla aXaX if (texto[posicion] == 'a') { for (int pos2 : X(posicion+1)) { if (texto[pos2] == 'a') { for (int pos3 : X(pos2+1)) ret.push_back(pos3); } } } // Regla bX if (texto[posicion] == 'b') { for (int pos2 : X(posicion+1)) ret.push_back(pos2); } // Regla b if (texto[posicion] == 'b') ret.push_back(posicion+1); return ret; } int main() { cin >> texto; bool primero = true; for (int x : X(0)) { if (primero) primero = false; else cout << " "; cout << x; } cout << endl; return 0; }
Lo anterior permite contar cuantos arboles de parsing hay, pues X(0).size() sera exactamente eso: el vector resultado devuelve exactamente un valor por cada arbol de parsing posible, y el valor indica en donde termina el parsing (lo que sirve dentro de propio algoritmo para saber desde donde se debe intentar seguir parseando).
De este modo, al ejecutar con aabbaba devuelve un arreglo {7}, que indica que hay un unico arbol de parsing que termina en 7. Como la cadena mide exactamente 7, significa que en este caso hay una unica forma posible de parsear el string completo. Si en cambio lo ejecutamos con aabbababbbbbbb obtenemos {7,14,13,12,11,10,9,8}, que indica todos los tamaños de prefijos que es posible parsear de acuerdo a la gramatica. Finalmente, para abababab responde {7,3,8,7,8,4}. Como el 8 aparace exactamente dos veces, hay exactamente dos árboles de parsing posibles para esta cadena de acuerdo a la gramática de arriba (pues el algoritmo explora todos los posibles exhaustivamente, probando en cada situación todas las posibles reglas que se podrían usar).
Notar que la ventaja de este método es que no hubo que pensar ningún tipo de predicción: copiamos las reglas de la gramática mecánicamente, y el algoritmo va probando todas exhaustivamente mediante backtracking, devolviendo todas las posibilidades siempre.
Algoritmos polinomiales
Como comentario final, existen algoritmos polinomiales que permiten parsear cualquier gramática BNF, como son el algoritmo de Earley y el CYK (de Cocke-Younger-Kasami). Si bien el planteo es diferente, en el fondo son algoritmos de programación dinámica que plantean estados muy similares a los del backtracking del parser recursivo descendente que vimos, pero al utilizar memoización, se evita recalcular un mismo estado muchas veces.